The closest thing I have seen to a digital brain that is built for and is open source so can be owned by individuals. Asked the devs to look at it and they came back with this architecture overview. We’re going to continue to investigate and see if we can get a hosted version up and running (if they don’t already have one) that can be used by a non techie.
Will post more updates here shortly and if anyone has experience with this service please post thoughts below:
How to run
- Install Postgres14 then follow the instructions below for each os
- Clone the repo
- Install virtual env with python 3.10 - python3.10 -m venv env
- Activate environment - source env/bin/activate (mac)
- Create a users folder in the base path
- Create .env file and copy contents of .env_sample to it
- Add open ai keey to OPENAI_API_KEY
- Configure database url properly
- Run uvicorn main:app –reload
- Go to browser, possible prompt to input OPENAI API Key
- Sign in, username = admin, password = admin
Common error = database name.
Architecture.
Architecture is strictly based on OpenAI LLMs
RAG PIPELINE = Pgvector for Postgres DB and Chromadb
Pgvectore is being used to create vector embeddings and they are being saved into a local chroma sqlite db
LLM roles
- Machine: A computer program aiming to fulfill user requests.
- Brain: An AI Brain Emulation tasked with updating user-specific data based on received messages, focusing on important information while discarding irrelevant details, within a word count limit.
- Subject: Identifying the observed entity in a given observation.
- Observation: Breaking down a last message into search queries to retrieve relevant messages with a vector search, following a specific format.
- Categorise_query: Categorizing a last message into a category and a search query to retrieve relevant messages with a vector search, adhering to a specific format.
- Categorise: Categorizing a last message into predefined categories, each on a separate line.
- Retriever: Breaking down a last message into multiple search queries to retrieve relevant messages with vector searches, following a specific format.
- Notetaker: An advanced note and task processing assistant, determining whether to add, update, delete, or skip tasks based on the last message and existing notes, following a specific format.
- Summary_memory: Summarizing current notes while maintaining essential details, excluding imperative instructions.
- Summarize: Summarizing the current message while maintaining all details.
- Date-extractor: Extracting the target date for the last message, providing it in specific date formats or ‘none’.
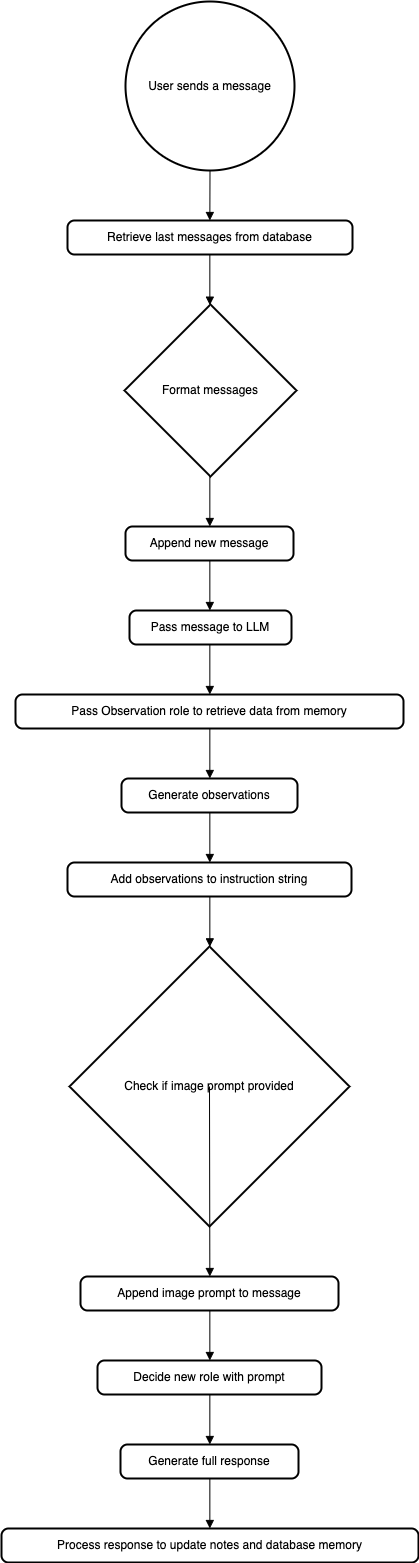
When a user sends a message, The last messages stored in the database are retrieved and formatted to the (role: assistant, content: “”) format and the new message is also appended. The message is then passed to the LLM and the Observation role is passed to retrieve some data from the memory. Observations are then generated and added to the instruction string. If an image prompt is provided, it is appended to the message. The LLM decides the new role with prompt and a full response is generated by the LLM, the response it also processed to update the notes and database memory
Deep Dive
When A user sends a message, the message is passed to a process_message function in the utils.py file. The user settings are then retrieved from the load_settings function. The previous messages are also retrieved through the get_recent_messages function. The function also retrieves data from the get_most_recent_messages which then refers to the get_memories that retrieves the “active brain” data from the collection, this get_memories sorts and filters the previous conversation and returns the last 100 which is then passed to get_most_recent_ messages for further sorting and then to the get_recent_messages for the final restructuring and assigned to a variable last_messages_string. Last_messages_string is the further formatted into a (user: message, assistant: message) string format and concatenated with the new message sent by the user (all_messages). The all message and new message along with some configuration data is then passed into the process_active_brain function.
In the process_active_brain method, the new message is split into chunks in the split_text_into_chunks function, and then appended to the active_brain collection database in the create_memory method which returns the create_memory function in the agentmemory/main.py. The all_messages is then passed to the LLM with role of retrieval. Personal fix: The response is then passed to the process_observation function to split the text into a list. The list is then looped through and each item is passed to the search_memory function, the result is then stored in the corresponding list in a process_dict dictionary. The method sorts the results list based on the distance and removes the result with the highest distance if the list contains more than one result. The method then generates the final result string and checks if it exceeds the remaining tokens. If it does, it removes the result with the highest distance until the token count is within the limit. The method also creates a set to store unique results and adds the results to the set. Finally, the method returns the result string, token count, and unique results.
In summary, the process_active_brain is responsible for processing the active brain and generating a response based on the user’s input. It handles memory creation, search queries, and token management to ensure the response is within the specified token limit.
In the process_message, the new message and all messages are also passed to the process_episodic_memory method, this method passed the messages into the llm with role of date-extractor, and the date extracted is passed to the search_memory_by_date with searches the collection table and filters the date by date. The result from the database and response from the LLM date-extractor is then returned. The all_message and new_message is also passed process_incoming_memory function in the memory.py file. In this function, the message is passed to openAI model with the categorise_query prompt which is determined by the get_role_content function (datetime.datetime.now() is also passed into the prompt with this function). The LLM then decides if the category is one of below:
- Factual Information
- Personal Information
- Procedural Knowledge
- Conceptual Knowledge
- Meta-knowledge
- Temporal Information
The Model response is then parsed into the process_category_query function which then returns a set of the category and the message.
Example 1 response = [(‘procedural_knowledge’, ‘calculate BMI’)]. (Query= “Can you calculate my BMI?”)
The response is then looped through and reformatted into a key, value format, with the input as the first key, value, and the category and responses from the model as the second key, value.
Example 2 = {‘input’: ‘can you calculate my BMI?’, ‘procedural_knowledge’: {‘query_results’: {‘calculate BMI’: }}}
This is then passed into the search_query function where a full searched result (plain text) and a process list of sets is returned.
In the Search query function, the query (query_results value in Example 2) is looped through, (it is converted to a list passed into the search query function) and the category and query is passed into the search_memory function in the memory.py file which then returns a search_memory function in the agentmemory/main.py file.
In the search memory function, the category is retrieved/created from the chromadb, the minimum number of results is then set to prevent searching for more elements than are available. The types to be included in the result is retrieved from the get_include_types. If filter_metadata is provided and contains more than one key-value pair, it maps each key-value pair to an object shaped like { “key”: { “$eq”: “value” } }. It then combines these objects into a single object with the $and operator. If novel is set to True, it adds a filter for memories that are marked as novel to the filter_metadata object. The function then performs a query using the query method of the collection, providing the query texts, filters, and other parameters. The result query is then passed to the chroma_collection_to_list to get the relevant data from metadata, documents, embeddings and distances table.
The process_incoming_memory also returns some data and some unique data just like process_active_brain, The unique result from both functions is then merged and formatted to retrieve the closest conversations based on similarity score.
The all_messages and new_message is also passed into the note_taking method, this method get the contents in the notes file and passes it to the LLM with the summary_memory role. The user message is also passed to the LLM with the role summarize, and the response from the LLM is concatenated with the current time, the response from summary_memory role LLM, the content of the notes and the response from summarize role LLM and assigned to variable called final_message, final message is then passed to the LLM with role note-taker. The response is then passed to the process_note_taking_query function to extract the action to be performed. (create, read, update, delete), any action specified is performed on the notes.
Finally, the messages, history_messages is passed to the generate_response function which returns the response from the LLM with the system_prompt prompt.
The content of the response is then extracted and passed to the process_response function, which updates the active brain memory through process_incoming_memory_assistant function.
The response from the process_response function is then returned to the user.